LDC Via: a new home for your organisation’s know-how
Another year!

It’s that time again, Christmas and the end of another year! Where do the days go… A year of extreme busy-ness at LDC Towers, we’ve had a lot of work on, and also a wedding! This all leads to general blog neglect. Shame on us.
Our venerable platform is happily serving up a multi-tenant web application for a big client, with more back-end changes afoot. Google apps script projects still abound, as do projects built using node. We’re still engaged with enterprise-scale migration projects, and we look after organisations from schools to insurance companies, finance outfits to consultancies. As ever, if you’re looking for assistance with your projects, by all means get in touch!
In March 2020, Engage 2020 comes to Arnhem, and I’m sure we will be there in some shape or form – have you registered yet?
For now, we wish you a peaceful, merry Christmas, happy holidays, and a splendid new year!
So that was Engage
Whilst we sponsored Engage this year, it was a slightly muted affair for LDC Via, as only one of the motley crew made it to the conference, alas. Theo and Hilde put on an excellent show at a stunning excellent venue: Autoworld, set in the beautiful Parc Du Cinquantenaire (AKA Jubelpark) in Brussels. Thank you Theo, you did it again!
Our diminution in numbers meant that we couldn’t run a stand this time round. Whilst that was a little disappointing, it did mean that for the first time in years, I could attend some sessions! The opening keynotes were interesting and well-presented: HCL and IBM both have a plan, and even some marketing! I particularly enjoyed the new format speed-sponsoring, ably wrangled by Mr. Tony Holder (and that has nothing to do with the fact that I won some beer. Cough).
From our perspective as a services organisation, it’s interesting to see other companies present their products. ISW’s commercial session on Kudos Boards was very good indeed; they’ve done a cracking job implementing this useful tool, and there are some interesting features in the pipeline too. Recommended!
Sadly we missed our friend Andrew with his session on Sphinx in favour of a DQL presentation from Tim Davis, but at least we can read the slides eh! (Danke für die Schokolade mein Freund!)
Update: here’s a link to Tim’s presentation on DQL.
In other news, hell froze over: I attended an administrators session… But not just any session, oh no! Gab ran through 60 Admin Tips in 60 Minutes which was fantastic, and sure to be useful as I flail around in the console.
Until next year.
Ben
Engage 2019
We are happy to announce that once again we have signed up as sponsors for the Engage user group conference in Brussels this year.
We have no idea whether — or how — we will get there, given the Brexit nonsense back here in Blighty, but we will try our best!
As a services organisation rather than “product vendors”, we feel it’s simpler just to attend and catch up with people, so we won’t be running a stand this time round.
The Engage conference takes place this year at Autoworld, which looks amazing. As ever, Theo chooses the most splendid venues.
Look forward to seeing you in May: come and find us, let’s talk!
New year lighthouse!
Happy new year (albeit a somewhat belated greeting on our part). Let’s hope 2019 brings us all some reprieve from the unrelenting bad news out there! They say that the key to happiness is dealing with what you can control, and so to that end we’re going to spend this blog post re-visiting an old tool that you may have ignored for a wee while – I know I have, given that my day-to-day work rarely includes front-end web development.
So: Lighthouse, a collection of open-source tools aimed at checking web pages for things like performance, accessibility, search engine optimisation (urgh) and general best-practice-type-stuff. The Lighthouse tooling was added to Google Chrome some time back; certainly version 3 has been there since Chrome v69.
Lighthouse is triggered by simply opening DevTools in Chrome, and selecting to run an audit on a given website. After it has done its thing, you are presented with something like this:
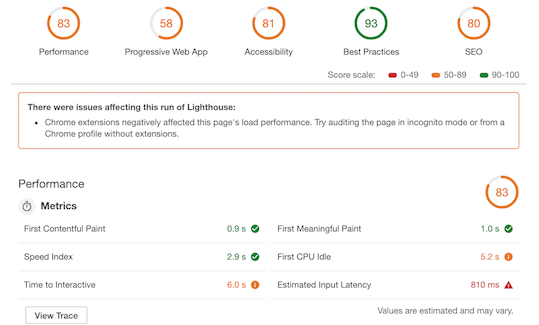
Once the tool has finished doing its thing, and the report screen is rendered, you can dive into all of the stats to your heart’s content. Clicking on each top-level circle provides a list of passes and fails, with onward links to aid remediation. Even in 2019, many web sites fall down on their accessibility scores – running Lighthouse on your site is a sobering experience.
2019: we’ve got lots to do, and I bet you do too. But what a nifty DevTool.
Migrating IBM Quickr
For the last eighteen months or so we’ve been engaged in a project to provide two things for a client:
- Migrate multiple IBM Quickr places to our platform, and;
- Develop a new web application to replace IBM Quickr, both for the migrated content, and for new places as required.
This is not an insignificant piece of work: Quickr was a content management platform that had a lot of investment from Lotus and IBM at various points, and it was around for a long time. Furthermore, once we had won the work and we were in the throes of advanced planning, we were also looking to undertake a massive re-write of the entire Via migration utility.
A re-write? Really??
Those who have been with us for a while will recall the web-based migration tool – still available on our site – which provides an excellent demonstration for part of what our platform does. However, if you are serious about bulk-migrating data: multi-NSF applications, mapping security fields, custom content, driving through schema changes and the like, then it’s our Java-based migration utility you need.
When we started to build Via over five years ago, we embarked upon an ambitious development programme: not only would we code the API layer, we would also build migration tooling ready for day one. This was admirable but misguided, because the upshot was that we were building direct-to-MongoDB migration code alongside the abstraction layer of our API. In short, the migration utility did not use our own API, which was clearly undesirable for all manner of reasons.
Opting to re-work the migration utility was therefore The Right Thing To Do. We simply had to mitigate that technical debt, take a deep (collective) breath and crack on. The Quickr migration project clearly underlined the need for a flexible, speedy migration path.
Almost every piece of code in the migration utility has been re-designed and re-written. We have multiple “importer” classes which can handle selection criteria at the form, document, view, database, directory and, of course, Quickr level. A “bootstrap” class orchestrates the import process, and handles everything from dynamic configuration loading to dealing with different types of directories for migrating user profiles too. We can even merge multiple Quickr places into one.
Want to know more? Fancy migrating from Quickr, or even Domino.Doc? (Yes, that too!) Drop us a line.
Use the cloud to liberate your organisation’s knowledge.
Quick links
Contact us
LDC Via Ltd.14 Rosebery Avenue
London
EC1R 4TD
United Kingdom +44 (0) 20 3633 3009
(9am - 6pm UK time) [email protected] A company registered in England & Wales, no. 09209489
© 2014 - 2025, all rights reserved. Terms & conditions